
While a rigorous defense of today’s post depends on understanding the six previous installments, the basic concepts should be fairly straightforward, and perhaps even self-evident in certain aspects. Hopefully, you’ll keep up just fine. Here’s a short synopsis, in advance:
Informational Redundancy enables cognitive chunking of familiar biographical sequences, but the resulting coherence of particular Life Stories varies widely because some serial patterns of biographical temporality are more common and more familiar than others.
To understand (in theory) how these variations can be measured comparatively (along a spectrum of “Narrative Redundancy”) we must illustrate-by-analogy. The bulk of this post will therefore examine the relative degrees of informational redundancy in thousands of uniquely patterned English words. Just as the most common letter patterns become mnemonically ‘unit-ized’ so that some words require less mental reconstruction to spell (that is, to ‘un-chunk’) than other words, so it is with remembering life stories. The more familiar biographical sequences offer greater redundancy and thereby take on a higher degree of narrative unity, while the less familiar biographical sequences present information with less available redundancy, which accordingly demands greater effort from reconstructive remembering.
Thus, by analogy, we demonstrate the way in which Biographical Redundancy is theoretically relative, and diversifies the middle range of storylines in our proposed spectrum of “Narrative Redundancy”.
And so, without further ado, we shall now try to unpack all that gobbeldygook!
~~~~~~~ Intro ~~~~~~~
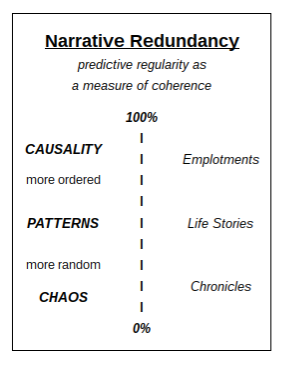
At the very least, we established in post 6 that coherence is relative. At the high end of the coherence spectrum are Emplotments, with chronological fabulas that are very easily reconstructed due to mnemonic advantages of story content that features causality. The highly temporal content of those cognitive storylines can approach 100% informational redundancy. At the low end of the coherence spectrum are Chronicles, which are very difficult to remember in serial order because each successive event in the chronological sequence seems somewhat randomly placed. The highly non-temporal content of those cognitive storylines can approach 0% informational redundancy.
With these two obvious poles, it was easy enough to propose that the broad middle of this coherence spectrum must include Life Stories, because the biographically temporal content of their linear fabulas tends to form patterns, which can be cognitively chunked (or “unit-ized”) by readers who have expert-level familiarity with longitudinal patterns of human existence. Up until now, however, this moderate level of mnemonic coherence has been ascribed to the lesser “Unity” of familiar patterns and cognitive chunking. What today’s post needs to accomplish, therefore, is to demonstrate that the broad middle can be assessed in the same terms as the top and the bottom. Today’s goal is to explain the relative coherence of biographical storylines in terms of informational redundancy. Thus, today’s post is called “Biographical Redundancy”.
It’s obvious enough that some Life Stories are more coherent than others, but how much more coherent? Can we comparatively, albeit hypothetically, measure the redundancy of a Life Story?
Although it’s clearly impossible to measure anything about the content of a fabula (which exists only in the memory of someone who has received a discourse), we can demonstrate that serial patterns can be individually comparable according to the “predictive regularities” of their content… that is, comparable according to the degrees of probability featured in moving from one bit of each series to the next bit in that series… or, in other words, comparable according to what Claude Shannon called informational redundancy. Again, we cannot even list what these bits of content might be (in the actual cognitive workings of any remembering mind), but with enough effort we could hypothetically build models of several biographical fabulas and then compare those all, collectively. Today, however, I’m going to take a much more feasible approach.
I will now attempt to illustrate the hypothetical comparability of a countless number of life story patterns, and I will do so entirely by recourse to analogy!
~~~~~~~ 1/3 ~~~~~~~
It is not at all trivial to point out that the acquisition of mastery in spelling requires expert levels of familiarity with a broad diversity of relativity common and uncommon sequential patterns. We usually take it for granted, but the ability to spell properly constitutes a mind boggling amount of cognitive chunking, without which the informational costs of remembering word forms would be practically and mnemonically insurmountable.
To understand cognitive chunking in terms of information, let’s jump back in time to about 80 years ago.
When Claude Shannon was pioneering the field of information theory in the 1940s, some of his early breakthroughs came by examining the ordered structure of words and letters. In 1951, he said, “anyone speaking a language possesses, implicitly, an enormous knowledge of the statistics of the language. Familiarity with the words, idioms, cliches and grammar enables him to fill in missing or incorrect letters in proof-reading, or to complete an unfinished phrase in conversation.” (Note: because Shannon was speaking about expert language users, this avoids controversies about language aquisition.)
One easy way to observe this “informational redundancy” in language is by removing vowels. For instance: “y cn rmv th vwls frm mst nglsh wrds nd stll cnvy th sm mssg”. This illustration proves vowels in English are somewhat “redundant” but observe also that in normal writing these redundancies are mnemonically advantageous. As readers, the extra clues help us feel more confident about basic decoding, and dealing with much less uncertainty helps the process go faster, securing effective transmission of the original message. In other words, the redundancy is precisely what provides opportunities for efficiency. (Hold that thought for a minute.)
Another type of redundancy that’s easily observed in English words is the frequencies of individual letters. Most Americans learn the ten most frequent letters (e, t, a, o, i, n, s, h, r, d) by playing Hangman or Wheel of Fortune, but the exact statistical measurements were generated first by cryptographers, who found it useful to know the exact letter frequencies when breaking a code. That kind of math gets more complex when you start observing that groups of letters form common patterns. For instance, the letter “t” is most often followed by “h”, “o”, “i”, or “e”. In turn, “th” is most frequently followed by “e” or “a”. Thus, we observe a variable pattern which begins many common words (the, then, they, their, that, than, thank), and we might also note that the most common chunks of letters are often made of individually frequent letters, and for that matter the most common English words often include frequent letter combinations.
Since these patterns are sequenced, we can often predict which letter is going to come next. This “predictive” function of sequencing letters is especially helpful in basic cryptography, telegraphy, and electronic messaging. For our purposes, this will simply illustrate the power of statistical regularities for recognizing variations in pattern. Shannon referred to all of this as “redundancy”, eventually estimating that the English language altogether was about 50% redundant. That is one reason why most people are able to learn thousands of words.
The high level of redundancy in most English words makes it easier to store them as cognitive chunks, and makes other words easier to reconstruct by remembering patterns. In all cases, redundancies help reduce the informational cost of learning new words (i.e., remembering new spelling sequences). Note that the phonetic compliment of each complete word is another mnemonic advantage, but phonetics alone cannot account for the development of expertise in spelling, which is why I remain focused on spelling in this post. It is in written form that the “whole word” remains most observably a lengthy, elaborate sequence of individual letters. To someone unfamiliar with written English, the combinations at first will appear to display tremendous randomness. However, with careful attention and a great deal of effort, the frequencies begin to appear more easily, and then one begins to observe frequent patterns, and learn common words. Eventually, once expertise is obtained, the entire complexity becomes easily managed.
The key point of all this for today is that frequency enables predictability. ((**Although we’ve progressed now in this series to declare, with significant nuance, that mnemonic reconstruction depends on “informational redundancy” - a.k.a. “predictability in retrospect” - but to understand what this means it can still be most helpful to simply think in terms of basic probability.**)) In colloquial terms: knowing the liklihood of possible outcomes makes it easier to guess (successfully, with fewer guesses) which outcome will (or, retroactively, did) actually occur. Again, probability assists prediction… and, by the same statistical accomodation, probability also assists reconstructive remembering.
If you were operating a telegraph receiver, waiting for the next letter to come over the wire, crypographic statistics would be helpful in predicting a transmission, bit by bit. In a similar way, today’s information scientists apply such “predictive regularities” in designing computer algorithms for sending and processing strings of data efficiently. (They call this “data compression”, which we’ll examine in Post #9, but for now let’s keep focused on “predictability”.)
If you’re reading only one letter at a time, “t” implies one or more of its probable subsequents. In some way, in the span of a split-second, your statistical knowledge actually helps prepare you to read the rest of the word. But from a broader perspective, what happens is that collections of these frequencies creates patterns that invite familiarity. On some deeper level your brain may know all the statistics. On a more conscious level, you simply wind up learning common words more easily because they build on high frequency letter combinations. These dynamics regularly assist readers, code breakers, telegraph operators, and the winners of spelling bees. What you and I call “predictable” can be called “redundant” in Informational terms.
((**For more on telegraph messaging, and a bit on the overlap between information theory and cognitive psychology, scroll to the bottom for excerpts from George Miller’s famous paper about “The Magical Number Seven”.**))
The point is that serial patterns can be understood as combinations of frequencies.
Here’s one example of a serial pattern that’s made up of frequencies.
Consider that the most common word in English (“the”) contains the two most common letters, and the 8th most common letter. From a causal standpoint, the word’s frequency is a big reason those letters are so frequent, but from a statistical standpoint (once the data is all in your head, so to speak) this causality is irrelevant. As an expert reader, you may consciously recognize the frequency of “the” but in doing so you also subconsciously recognize the frequency of “t” and “e”. The serial patterns which occur frequently enough to become familiar to us are often made up of individual elements which are common and familiar to us already. I say “often” of course because general frequencies aren’t uniform across all sub-groups of data. For example, “h” is the 8th most common English letter but it rises to 4th most common in the top 100 English words (in which sub-group, “e” is still 1st and “t” holds 3rd place), and the letter “h” is also less common in long words than short words -- which justifies your surprise when I said that “h” was ranked 8th overall, and which also explains why “h” is overrated for playing hangman or Wheel of Fortune. The high ranking of “h” is entirely due to its ubuiquity in high frequency words like: {this, that, these, those, then, than, them, there, they, their, his, her, he, she, who, what, how, which, when, with}, and - above all - “the”. All this underscores my main point. You recognize “the” all the more easily because “h” is extremely common in those kinds of basic formations. Patterns are all the more frequent when they combine elements which are frequent, or at least include some high frequency elements. The second most common word (“be”) is helped a lot by its second letter, and the word “just” (57th most common) benefits greatly from including “t” (2nd) and “s” (7th). That word would have been far more difficult for you to learn (for you to “chunk as a unit”) if it had been spelled “juxk”. (Note: our focus is not here on the initial acquisition of spellings, but a bit of thinking about acquisition can help illustrate my central point.)
In all this, I still have only one point, which I will now repeat.
Serial patterns are, in fact, combinations of various frequencies.
Therefore, if the underlying frequencies are comparatively measurable, according to statistical probability, then serial patterns built of those frequencies can also be measured - according to some rubric or another - by considering serial patterns as chains of probability.
~~~~~~~ 2/3 ~~~~~~~
As it is with spelling, so it is with biographical fabulae. In serial patterns, comparable according to frequency, predicting the story’s chronological structure (or “forwardly reconstructing” the sequence) is a matter of recognizing familiar combinations of probable outcomes. This is a core principle of what information theory is all about, the recognition of implications. To be “informed” is literally to see one step ahead.
It was no coincidence that William Friedman determined the informational content of a memory is what indicates its own temporal consequent (or subsequent). In cognitive terms, we remember “the time of events” whenver one eventful trace memory is able to direct (i.e., “inform”) the remembering mind about which event followed it (or, inversely, which event it followed). We discussed this at length in post 2 and post 3, where I listed several examples, such as: recalling Johnny’s high school graduation can guide my attempt to recall trace memories about Johnny in college, or the army, or some kind of vocational training. Of such remembering, Friedman would say the memory is sequenced by its relationship to a known time pattern. In those posts, I only added that Johnny’s life story might fit one of several known patterns, some of which we recognize as relatively more frequent than others. Now, in post 7, we are able to consider all this more precisely in informational terms, but the central concept has not changed. In essence, these informational underpinnings merely help to explain the fact that our familiarity with common serial patterns is what helps us reconstruct mnemonic content with a chronological structure.
That said, the explanatory power of information theory is the only means I have yet found by which to integrate all these various aspects of my developing thesis about Time in Memory.
If we understand “pattern” as a collection of frequencies, Freidman’s work integrates even more closely with Shannon’s. Whenever we recall only the first step in a recognized time pattern, the challenge of reconstructing the whole pattern is functionally the same task as a telegraph operator trying to predict the next letter of an incoming transmission. That’s also the same task that stands before any computer program that’s receiving a communication one bit (or “piece”) at a time. To go back to Johnny, recalling his graduation is the same as observing a “T” and predicting that “he” or “his” or “hat” might come next. It’s our general knowledge of broad statistical patterns that enable successful prediction, and it is likewise the broad variety of familar patterns in Life Stories which enables us (often, not always) to remember biographical content in chronological sequence with coherence. Since biographical sequences are entirely arbitrary, that is no small accomplishment.
The gradual way in which people become familiar with hundreds of variably structured life stories is a process of chunking with expertise, which requires a vast statistical knowledge of longitudinal patterns. It’s this same kind of process that enables us to spell thousands of variably sequenced letter combinations. On some level, our brains detect and evaluate individual probabilities on a comparative basis for predictive discernment, but on some other level we simply grow accustomed to familar serial patterns as a regular type of rememberable content.
If we undertook a perfectly careful and rigorous analysis, we might break down many of these patterns into their statistical components -- for biographical content, we would analyze our own modeling of such patterns -- but from a broader perspective we can simply observe that demonstrating a variety of patterns indicates an underlying statistical diversity. Hypothetically, any collection of patterns could be measured comparatively and ranked according to informational redundancy. More generally, if we have a broad collection of serial patterns, of demonstrably varying regularity and overall frequency, then that collection itself serves as evidence of the diversity in statistical frequencies which undergirds any similar set of comparable serial patterns. Theoretically, all we would need to do is isolate each segment (or model the event sequences) and gather a large enough set of statistical data against which to compare each particular sequence.
Obviously - as I said near the top - the subjectivity of our cognitive processes prevents us from doing this. However, it should be equally clear that our remembering minds have subjectively made such judgments already. Somehow, our cognitive faculties have been busy at this work for our whole lives, invisibly compiling the vast set of statistical knowledge for as long as we have been paying attention to the long-term changes that we observe to be relatively common in different people’s lives. The work we cannot do objectively, together, has already been done in some way by our minds, individually. This is all of the work that went into developing our biographical expertise, and it can also - therefore - be understood in informational terms.
Serial patterns are combinations of frequencies, and when each item in the series helps us “predictively” reconstruct the next item, then we can begin to repeat that serial reconstruction more and more quickly. This reconstructive advantage is what enables us to become familiar with serial patterns, and eventually -- all the while building upon the foundation of predictive regularity -- to memorize whole sequences as single units.
Thus, probability undergirds the mnemonic coherence of familiar sequences.
Thus, biographies are not merely a broad category in between plots and chronicles.
The informational redundancy of various life stories can be observed to approach lower range of emplotments, when the biographical storyline has been somewhat more heavily narrativized. The informational redundancy of various life stories can be observed to approach the upper range of chronicles, when the biographical storyline has been allowed to remain much more arbitrary.
The informational redundancy of various life stories can be observed to approach lower range of emplotments, when the biographical storyline has been somewhat more heavily narrativized. The informational redundancy of various life stories can be observed to approach the upper range of chronicles, when the biographical storyline has been allowed to remain much more arbitrary.
The relative coherence of storylines is not, therefore, a separate issue within three genres or theoretical categories The relative coherence of storylines can be plotted along an infinite range of constructive rememberability. Therefore, Narrativization is not a categorical phenomenon.
Narrative coherence is - strictly speaking - entirely relative.
~~~~~~~ 3/3 ~~~~~~~
Mathematically, how should we theorize this “unified continuum of narrative redundancy”? The entire range, top to bottom, can be considered in terms of statistical probability, but individual storylines can also be thought of as informational “patterns”.
Technically, “pattern” includes anything that’s predictable between a 99.9% and a 0.01% probability. A chain of dominoes makes a beautifully predictable pattern because you know what’s coming next with 99% certainty, right until the moment it ends. A shuffled deck of cards starts out as an entirely unpredictable pattern because you have no way of determining which card will turn up first from the deck. Each time the dominos fall, it’s still 99% predictable, and each time the deck gets shuffled, the first card is 0.01% predictable. Through repetition, your mind recognizes that series of outcomes as familar serial patterns.
Pattern is probability and probability is pattern. Each term can be useful for describing various aspects of this conversation. The broadest, most accurate term is still “redundancy”, but “probability” remains the most accessible term. Either way, we’re still theorizing various sequential productions (or reproductions) of a series of data points, and the informativity of data is measured on a scale between randomness and certainty.
That's what information is, really. It's data which actually happens to inform you about something. To put that another way, the informative value of data is a measure of how much new knowledge each piece of data does or does not actually provide.
Total uncertainty measures at zero percent probability (no discernable pattern at all) and total certainty measures at one hundred percent probability (the ideal pattern to work from). Total uncertainty (zero pattern) is like the sequence of black and white pixels in a screen full of old TV static. That’s what we call “random chaos”. Total certainty (absolute pattern) is a dark black screen with no lit pixels or a bright white screen with fully lit pixels. That’s what we call “uniform structure”.
Perfect predictability describes a string of ones or a string of zeroes. Both sequences are near the top of the probability spectrum, because after a thousand entries turn up the same you’re pretty well convinced of what the next one will be. These perfect strings are also “perfect patterns” except it wouldn’t seem right in colloquial terms Nevertheless, uniformity is a pattern. The entire spectrum of Narrative Redundancy can be defined as a collection of informational patterns… and those patterns are measured according to probability… which means the amount of predictability… a.k.a. informational redundancy… in each particular string of narrative “data”.
Let’s break this down a bit further.
There are many kinds of events we’d call “highly probable” (i.e., greater statistical frequencies) and ***theoretically*** the probability of such events would be indicated by the frequent recurrence of said events in the universal set of statistical data which lists all known events of the past. Obviously, there are many reasons why we cannot generate a universal set of such data, although we could do so for something like the frequencies of letter sequences in English words. Nevertheless, insofar as the analogy holds, we could hypothetically compare all serial patterns that are made up of temporal content, provided only that we could generate enough comparable data.
If we did generate all such narrative sequences, what would we find? At the upper range, it wouldn’t occur to us to use the term “patterns” to describe highly structured sequences like the Iliad or the Odyssey. Nor would we think we saw “patterns” occurring down at the lower range, where sequences appear to be largely if not totally unstructured. No, the area in which we’d naturally think to apply the term “patterns” would be somewhere near the middle, where arbitrary sequences tend to contain subsequences which repeat fairly often. But pleast, note this well! That last sentence does not say we’d see one sequence that contains within itself some kind of often repeating subsequence. Rather, what we would find -- on this infinitely large collection of all conceivable life story fabulas -- is a very large set of individual life stories in which a particular subsequence would be evident. That is, to our perusal, that subsequence would be repeatedly evident. In this thought expierment, that would be the actual basis for recognizing one individual life story as containing a recognizable “pattern”. Furthermore, and merely to whatever extent it might be fair to say that this thought experiment modestly reflects our own recursively cognitive compiling of all available biographical data, that kind of broad perusal of countless individual life stories would be the only justifiable basis for recognizing one individual life story as containing a recognizable “pattern”.
Thus, in our diagram of this spectrum of Narrative Redundancy, the mid-range of the spectrum is labeled with the term “patterns” because this is where all the patterns appear that we tend to discuss as such.
While the most easily rememberable sequences involve 100% probability (narrativized causality), and the least easily rememberable sequences involve 0% probability (random chronicles), there’s a vast swath in the middle which includes the most common sequences that we actually recognize - and these sequenes (as we perceive and/or read about them) are neither extremely random nor extremely predictable. Now, within that “middle range” of recognizable (and not so heavily narrativized) Life Stories, there is a variable range of rememberability which depends on the regularity of that particular biographical sequence. The more heavily patterned an individual life story might be, the more likely our minds will be able to “unit-ize” that life story as a familiar serial pattern, as a “chunk” of recognizably human (albeit arbitrary) growth and development. In informational terms, that “familiar serial pattern” will have been “unit-ized” precisely because its represented event sequence reflects a high degree of predictability (i.e., “informational redundancy”).
Thus, “Biographical Redundancy” describes a large amount of this middle range in the larger continuum of “Narrative Redundancy”. Nevertheless, that middle absolutely stretches in both directions, so that it is (theoretically) a true spectrum of radically differentiated storylines.
Perhaps Literary experts who read this will be able to give more examples of published fiction and non-fiction stories which exist in-between the classic formulations of biographies and emplotments. Before they give their expert opinions, let me suppose that this overlap (NB, not “boundary” but “overlap”) could include early british novels like Pamela, Oroonoko, and Robinson Crusoe. Personally, I think the overlap (between biographies and chronicles is fairly easy to identify. First, we trend a bit downwards when individual life stories become more and more arbitrary, with biographical sequences which seem more uniquely random. Second, we trend towards true chronicles when an individual biographies give way to collective biographies, including family histories and some types of “history from below”. The lower-overlap-range might also include elaborate fictions like Tolstoy’s War and Peace or Hugo’s Les Miserables. Of course, it’s possible many readers would construct a highly coherent fabula of Les Miserables by focusing only on Jean val Jean, but readers know that Hugo’s actual novel is a cacophony of subplots and lingering personal backstories that are exhaustively detailed. Likewise, I’m not sure where we might put the novels of Charles Dickens because the structure of those fabulas would depend on just how many extended episodes and subplots of his interminable storytelling some individual reader might happen to recall. Actually, those last two examples are as good a reminder as any that this spectrum of coherence is a theoretical project. In particular, it can easily be blown to bits by experimental narratives like Ulysses or the entire tv series of LOST, but in general I do believe this will prove to be fruitful in various applications. Time will tell, but now I have truly digressed...
Here is the central point to which seven super-long blog posts have now brought us. The coherence of storylines varies wildly, rather than categorically, and all types of stories can be measured comparatively according to informational redundancy. This completes the introduction to “Narrative Redundancy” which I began in part 6.
Life Stories which seem objectively arbitrary can be relatively easy to remember as long as an individual is familiar with common patterns of biographical sequence. That may not quite measure up to most narrativized histories, but it’s a significant advantage - and a paradigm buster - and I humbly submit this theory deserves a great deal of further attention.
~~~~~~~ Epilogue ~~~~~~~
That last paragraph was my conclusion for part 7, today.
However, with regard to the coherence of Biographies, as a genre, there is one thing I’ve left out.
Today’s post revealed - perhaps most surprisingly - that biographical narratives are stories in which coherence depends on a broad familiarity with other similar stories. This is a key observation, with tremendous theoretical implications, but it doesn’t necessarily apply to all biographical storylines. Strictly speaking, this only applies to Life Story fabulas when the remembered timeline is reconstructed from start to finish (birth to death) in the forward direction.
As I pointed out in posts 1, 2, and 3, there’s an even stronger mnemonic advantage that comes into play when our minds can reconstruct biographical content in the backwards direction. Of course, this depends on the content of individual life stories as much as readers’ cognitive capacity and reconstructive aptitude, but as often as these dynamics are all put in play it takes the potential coherence of a biographical fabula to a much higher point on the scale.
Quite often, the biographies traditionally recognized as being more heavily narrativized are those which employ a strong dose of teleology.
Rather than reconstructing a serial pattern with modest coherence by remembering it “forwardly” in bits and chunks, a life story that features Teleological Redundancy can have its whole sequence summarized in its ending.
Fortunately, this popular dynamic won’t take very long to illustrate and explain.
Come back in a month or so for part 8 out of 10...
************************
Begin Bonus Content:
As promised, here are several relevant excerpts (bulleted) from George Miller’s famous work following Shannon, in 1951:
- … we must recognize the importance of grouping or organizing the input sequence into units or chunk. Since the memory span is a fixed number of chunks, we can increase the number of bits of information that it contains simply by building larger and larger chunks, each chunk containing more information than before.
- A man just beginning to learn radiotelegraphic code hears each dit and dah as a separate chunk. Soon he is able to organize these sounds into letters and then he can deal with the letters as chunks. Then the letters organize themselves as words. which are still larger chunks, and he begins to hear whole phrases. ... surely the levels of organization are achieved at different rates and overlap each other during the learning process. ...the dits and dahs are organized by learning into patterns and that as these larger chunks emerge the amount of message that the operator can remember increases correspondingly. ...the operator learns to increase the bits per chunk.
- In the jargon of communication theory, this process would be called recoding… There are many ways to do this recoding…
- recoding is an extremely powerful weapon for increasing the amount of information that we can deal with. In one form or another we use recoding constantly in our daily behavior.
- ...the concepts and measures provided by the theory of information provide a quantitative way of getting at some of these questions… a yardstick for calibrating our stiumulus materials and for measuring the performance of our subjects.
- Informational concepts… promise a great deal in the study of learning and memory… A lot of questions that seemed fruitless twenty or thirty years ago may now be worth another look.
For reasons I am not equipped to explain, Miller’s prediction was delayed by several decades. One hunch I will admit nursing is that information theory requires complex statistical algebra, and it seems likely the popular front of the new wave of “cognitive psychology” in the 1960’s and 70’s either wouldn’t or couldn’t engage with such high level math. I have heard rumors to that effect, and it would make tons of sense, but it's moot at this point, and who really knows.
At any rate, it's wonderful that there seems to be a positive new trend in the 21st century in which research psychologists are paying more attention to information theory when looking at cognitive issues of learning and memory. For today, this is all by the by, and frankly beyond my own understanding, but I do think I know enough to believe we should be hopeful about this development. I can at least say that some papers I barely understand have nevertheless been encouraging to me in my ongoing development of this theory about Time in Memory.
Anon, my friends…
************************
End of Bonus Content